Home Prediction of the quality of physical exercise on the basis of accelerometer data
Post
Cancel
Prediction of the quality of physical exercise on the basis of accelerometer data
Moritz Körber on Jul 24, 20192019-07-24T00:00:00+02:00
Updated Oct 1, 20252025-10-01T20:43:32+02:0011 min read
Background
Going to the gym, whether to boost your health, to lose weight, or simply because it is fun, is certainly a worthwhile activity. FiveThirtyEight recently reported that according to the latest Physical Activity Guidelines for Americans, every form of activity counts. However, if you have eager goals, not only quantity but also quality and being efficient matters. In this project, I predict whether a certain exercise, a barbell lift, was well or sloppily executed on the basis of data obtained from accelerometers on the belt, forearm, arm, and dumbell of six participants. The participants performed the exercises correctly and incorrectly in five different ways.
The idea for this analysis stems from the Coursera course Practical Machine Learning by Johns Hopkins University. The data for this project come from http://groupware.les.inf.puc-rio.br/har.
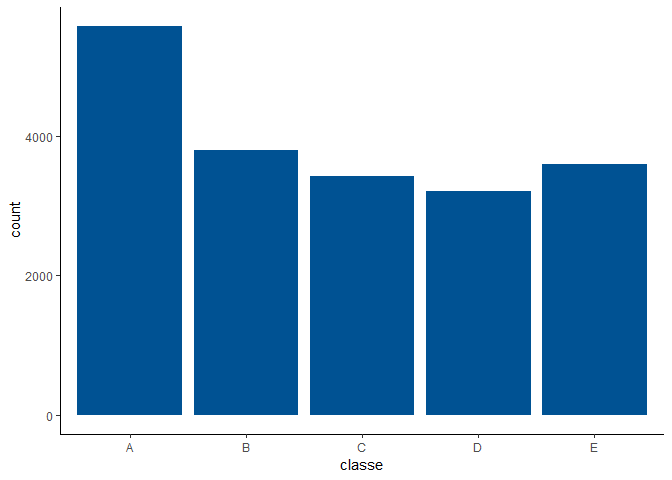
First, I am looking at the target variable classe. What type is it, how many “classes” are there in the data set?
1
glimpse(df$classe)
1
## chr [1:19622] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" ...
Since it is a categorical variable, the analysis represents a classification problem. Hence, an algorithm like logistic regression or random forest is suitable. Let’s check if the classes are balanced:
The same goes for features that contain mostly NAs. I chose a cut-off of 97.5%, i.e. I remove a feature if 97.5% or more of its cases are NA. Before I mindlessly discard these predictors, I am having a closer look at them – cut-offs are comfortable but may be nonsensical sometimes.
## Warning: funs() is soft deprecated as of dplyr 0.8.0
## Please use a list of either functions or lambdas:
##
## # Simple named list:
## list(mean = mean, median = median)
##
## # Auto named with `tibble::lst()`:
## tibble::lst(mean, median)
##
## # Using lambdas
## list(~ mean(., trim = .2), ~ median(., na.rm = TRUE))
## This warning is displayed once per session.
1
2
3
4
# check these variablesvis_miss(df[which(p>0.975)],sort_miss=TRUE,warn_large_data=F)
1
2
# remove them if sensibledf[which(p>0.975)]<-NULL
Highly correlated features contain mostly the same information. Hence, keeping both does not have any value at best and hurts fitting the model at worst. I am looking for features that are highly correlated for this reason and discard them if it seems sensible.
## Compare row 11 and column 2 with corr 0.992
## Means: 0.266 vs 0.165 so flagging column 11
## Compare row 2 and column 5 with corr 0.981
## Means: 0.247 vs 0.161 so flagging column 2
## All correlations <= 0.98
1
## [1] "accel_belt_z" "roll_belt"
There are two variables with a very high correlation. I will leave them in the dataset for this time, but performing the rest of the analysis without them is certainly an interesting alley to go down.
The mlr package provides a similar, more concise function:
1
findLinearCombos(nums)
1
2
3
4
5
## $linearCombos
## list()
##
## $remove
## NULL
3. Visualize the data
Time to take a step back and to have a look at the result of these cleaning steps.
1
vis_dat(df,warn_large_data=F)
Let’s see if there are mixed data types within a single feature.
1
vis_guess(df)
Plotting the relationship of the features with the target, classe, yields a first glimpse on potentially meaningful features.
Looks fine, let’s save the progress! We can now tinker around with a clean data set and can always return back to this state.
1
saveRDS(df,"1_data/cleaned_data.rds")
4. Training
Since the training is a bit computational heavy, I outsourced this step and brought an Amazon AWS EC2 t2.2xlarge instance into play. I performed the training steps shown down below on this instance and then transferred the results to my own machine. Here are the details on its environment:
What do we want our machine to learn? I first need to specify the data set and the target for prediction, here classe. In the mlr package, this is done by defining a task:
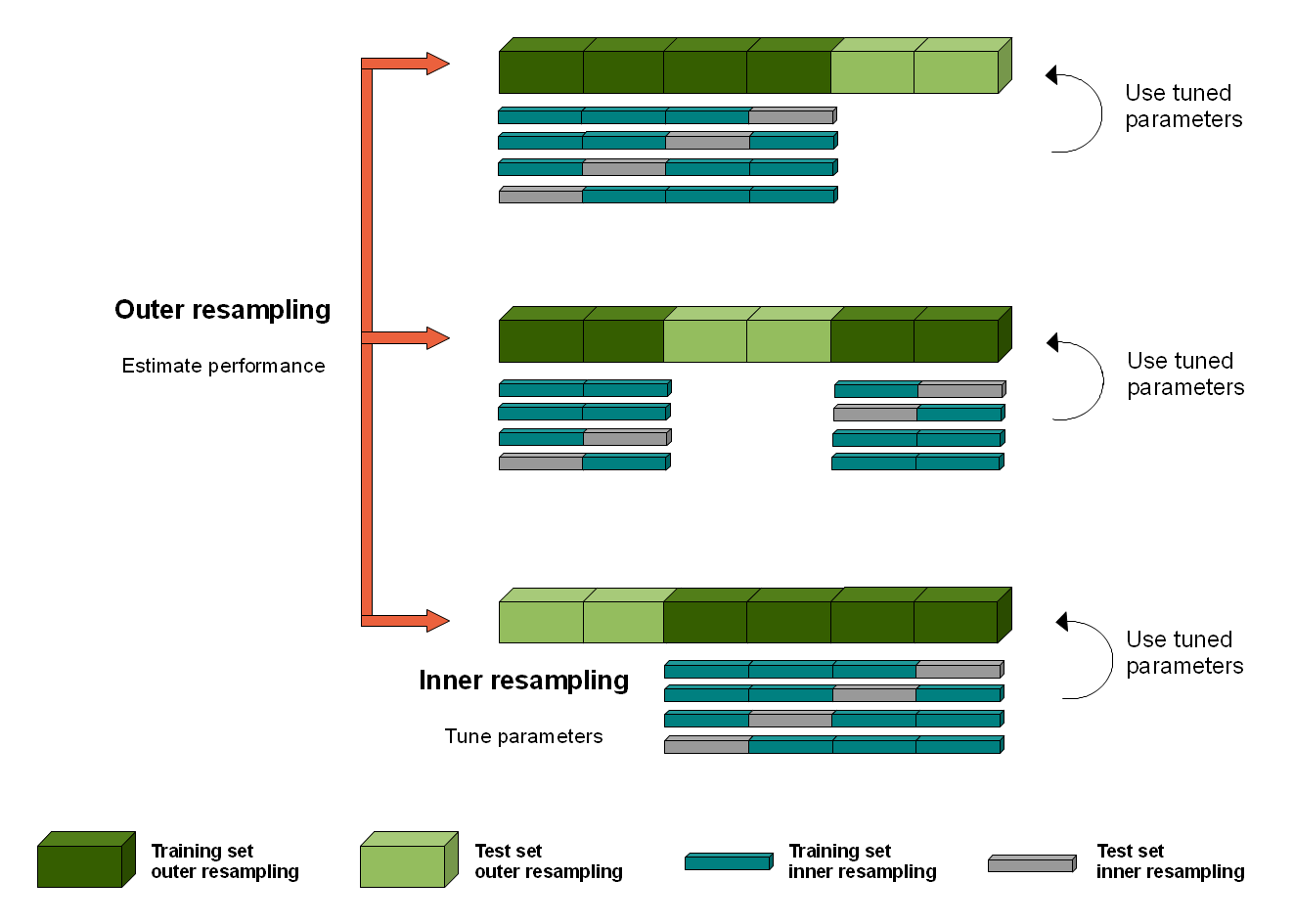
I chose to use a nested cross-validation strategy with a 5-fold inner cross-validation plan and a 3-fold outer cross-validation plan. Following the 3-fold outer cross-valdation plan, the data set is first split into 3 folds. Evaluation of the test error and hyperparameter tuning are performed using two of these folds by 5-fold cross-validation, the inner cross-validation plan:
1
rdesc.inner<-makeResampleDesc("CV",iters=5)
The best parameter combination is then evaluated against the remaining fold of the 3-fold outer cross-validation plan:
The mlr homepage provides a great graphical representation of this strategy here.
Note that the illustrated strategy uses a different number of folds.
Measures
Since it is a classification problem and the classes seem to be balanced, I chose the mean misclassification error to evaluate the learners’ performance. Other metrics, such as accuracy or F1-score, would also have been suitable and are easy to add if necessary.
1
measures<-list(mmce)
Learners
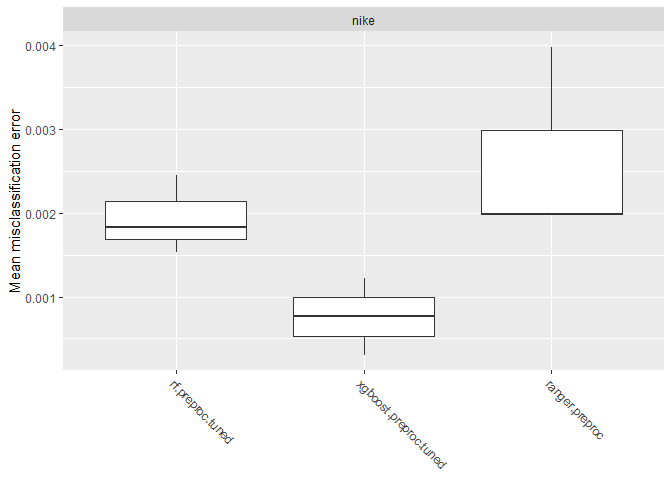
I compare the performance of three different learners: a random forest, XGBoost (a gradient boosting algorithm), and a ranger (a fast implementation of random forests). Each learner’s hyperparameters are tuned in the cross-validation process. For preprocessing, I center and scale the features. Here are the leaners’ instantiations:
## Warning in makeParam(id = id, type = "numeric", learner.param = TRUE, lower = lower, : NA used as a default value for learner parameter missing.
## ParamHelpers uses NA as a special value for dependent parameters.
The XGBoost algorithm seems to do the best job here. Thus, I concentrate on this learner and go on with extended hyperparameter tuning. Next, I train the final model on the complete training data set and discard all others but the best performing hyperparameter set.
The last step of this analysis is to predict a small, completely new, and independent test set. First step again is to load the test data.
Load and prepare test data
1
2
3
4
5
6
7
8
testing<-read.csv("1_data/pml-testing.csv",na.strings=c("NA","NaN","","#DIV/0!"),row.names=1)# make sure that they have the same columns (except the target)df%>%select(-classe)%>%colnames()->varstesting<-testing[vars]
Prediction
I use the model trained above to predict the 20 cases in this final test set.
## response true_labels correct_prediction
## 1 B B yes
## 2 A A yes
## 3 B B yes
## 4 A A yes
## 5 A A yes
## 6 E E yes
## 7 D D yes
## 8 B B yes
## 9 A A yes
## 10 A A yes
## 11 B B yes
## 12 C C yes
## 13 B B yes
## 14 A A yes
## 15 E E yes
## 16 E E yes
## 17 A A yes
## 18 B B yes
## 19 B B yes
## 20 B B yes
Seems like the learner did a great job! It predicted every case correctly. Yay! :)